if (!require("rforalle")) install.packages("rforalle")Loading required package: rforallelibrary(rforalle)
hent_data("kap06_slag.csv")Laster ned 'kap06_slag.csv' til /home/thomas/repos/github/rforalle_net ..df_slag <- read.csv("slag.csv")| FORBEREDELSER | - Opprett et R-prosjekt kalt kap06 som en undermappe i mappen rbok og jobb derfra. - Installér pakkene du trenger med install.packages(c("timelineS", "ggplot2", "ggeasy", "ggimage", "forcats", "ggraph", "DiagrammeR", "rsvg", "DiagrammeRsvg", "devtools")) og devtools::install_github("hegghammer/rforalle"). - Last ned koden i dette kapittelet med rforalle::hent_kode("kap06.R"). |
Det er ikke alt som kan fremstilles med grafer og kurver. For å visualisere kronologier, prosesser, eller relasjoner mellom ting, må vi ty til diagrammer av ulike slag, og her kan R være til stor hjelp. I dette kapittelet skal vi lære hvordan vi kan lage pene tidslinjer, prosessdiagrammer og andre diagramtyper i R. Figur 1 viser noen av illustrasjonene vi skal lage.
timelineS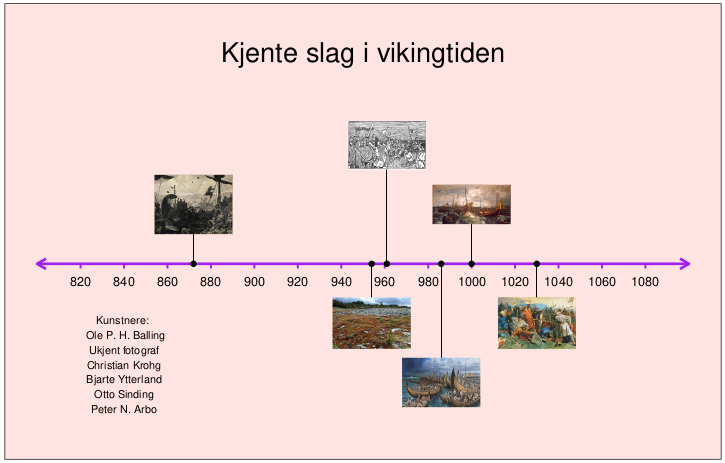
ggplot2.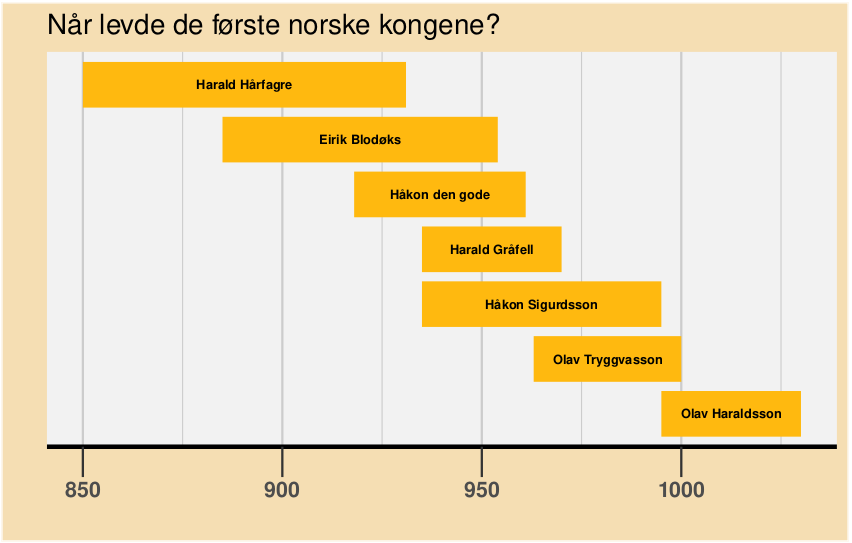
Tenk deg at du er historielærer og trenger en kronologi over kjente slag i vikingtiden. Du kan alltids lage det i Excel, men du vil da være ganske bundet til Excels grafiske uttrykk, og prosessen vil involvere mye klikking som du ikke nødvendigvis husker til neste gang du trenger en tidslinje. Lager du den derimot med kode, er det nesten bare fantasien som setter grenser for det designmessige, og når du trenger en ny, kopierer du bare koden og justerer det som trengs. I R er det lett å lage pene, repliserbare tidslinjer, ikke minst med pakken timelineS.
timelineStimelineS (merk stavingen med stor S) gjør opptegning av tidslinjer til en lek. Det eneste du trenger er en dataramme med navn på hendelser i én kolonne og datoer i den andre. Du kan lett lage en slik dataramme selv, enten ved å bygge den opp med R-kode (se kapittel 4) eller fylle inn et regneark. Men til dette eksempelet skal vi bruke en CSV-fil som jeg har forberedt og som ligger i dataarkivet under navnet “kap06_slag.csv”. Vi kan laste den ned med rforalle::hent_data() og laste den inn i R med read.csv().
if (!require("rforalle")) install.packages("rforalle")Loading required package: rforallelibrary(rforalle)
hent_data("kap06_slag.csv")Laster ned 'kap06_slag.csv' til /home/thomas/repos/github/rforalle_net ..df_slag <- read.csv("slag.csv")Deretter tar vi datarammen nærmere i øyesyn med str() og head() slik vi lærte i forrige kapittel at vi alltid bør gjøre. Om du vil, kan du også se på den med View(df_slag).
str(df_slag)
head(df_slag)Vi ser at df_slag har seks rader og fire kolonner. Hver rad er en hendelse, og for hver rad har vi en hendelsesbeskrivelse (navn), et årstall (år), en lenke til et bilde (bilde) og opphavet til bildet (kunstner). Bildeinformasjonen er overflødig; det er egentlig bare hendelsesbeskrivelsen og årstallet vi trenger akkurat nå.
Den eneste lille komplikasjonen er at timelineS vil ha tidspunkter som datoer i formatet “ÅÅÅÅ-MM-DD”, mens vår vektor df_slag$år bare inneholder årstall. Men vi kan omforme årstallene til datoer ved å legge til en fiktiv dato, f.eks. 1. juli. Til dette bruker vi bare paste0() og legger til strengen “-07-01”. I tillegg må vi omforme datostrengene våre til datatypen “date” med funksjonen as.Date().
df_slag$år <- paste0(df_slag$år, "-07-01")
df_slag$år <- as.Date(df_slag$år)Nå som vi har en kolonne med gyldige datoer, kan vi tegne opp tidslinjen med funksjonen timelineS() (se Figur 2). timelineS() trenger i utgangspunktet bare en dataramme som argument. Så lenge første kolonne er hendelsesbeskrivelser og andre kolonne er datoer, gjør funksjonen resten selv.
if (!require("timelineS")) install.packages("timelineS")Loading required package: timelineSlibrary(timelineS)
timelineS(df_slag)
timelineS uten modifikasjoner.
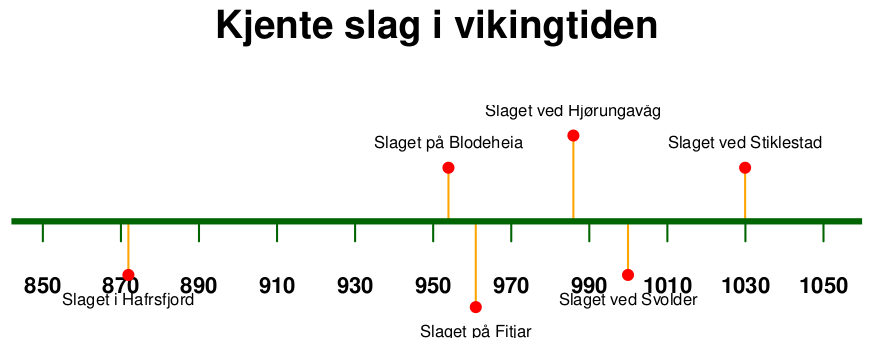
Vi ser at dette skal være en tidslinje, men det er mye som bør rettes på. Det er for mange vertikale markører langs tidslinjen, og årstallene er ikke runde tall. Vi bør også ta bort datoene fra hendelsesbeskrivelsene og legge på en tittel. Litt farger hadde også gjort seg. Alt dette kan ordnes med parametere inni funksjonen timelineS, for eksempel som følger (se Figur 3):
timelineS(df_slag,
main = "Kjente slag i vikingtiden",
buffer.days = 8000, # Antall dager forlengelse på hver side
line.width = 5, # Tykkelse på tidslinjen
line.color = "darkgreen", # Farge på tidslinjen
scale = "20 years", # Intervaller langs tidslinjen
scale.cex = 1, # Fontstørrelsen på årstallene langs tidslinjen
scale.tickwidth = 3, # Tykkelsen på de vertikale taggene
labels = paste(df_slag[[1]]), # Hvilke data som skal utgjøre teksten
label.color = "orange", # Farge på linjen mellom hovedlinjen og titlene
label.cex = 1,
point.color = "red", # Farge på punktmarkøren
)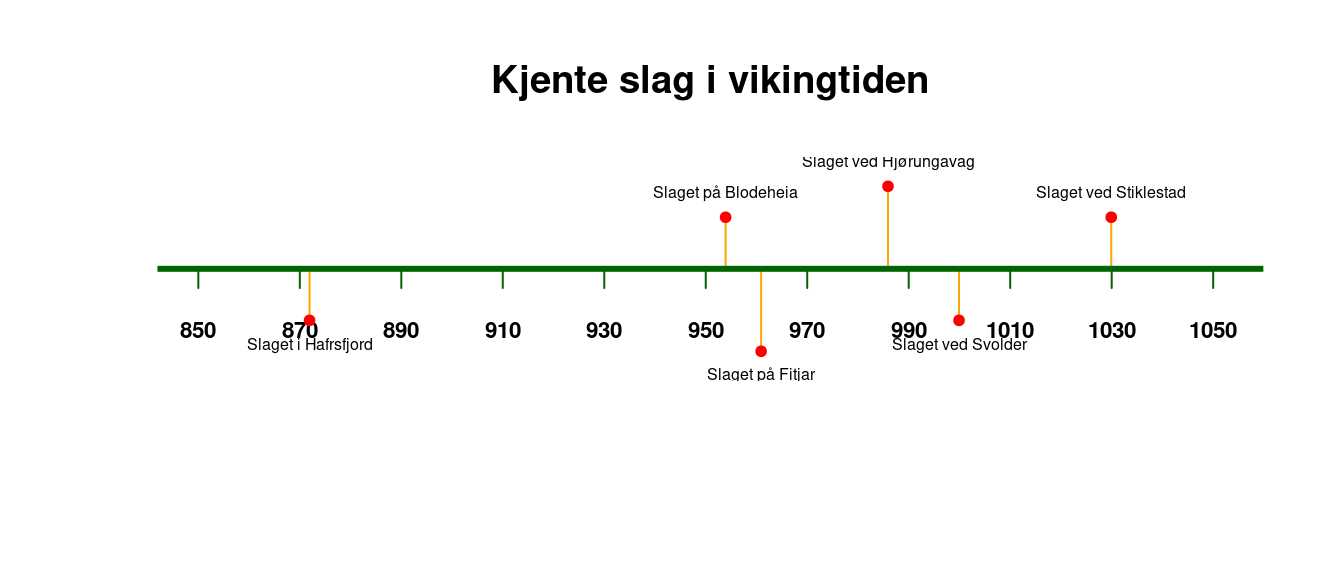
timelineS.
Under panseret bruker timelineS funksjonen plot() fra grunninstallasjonen, så vi kan lagre tidslinjen til et bilde ved å kjøre koden igjen mellom png() og dev.off() slik vi lærte i kapittel 5. Koden vil se ut som følger. Merk at hvis du øker bildets bredde og høyde, vil fonten fremstå mindre, og vice-versa.
png("tidslinje.png", width = 1000, height = 600, units = "px")
timelineS(df_slag,
main = "Kjente slag i vikingtiden",
buffer.days = 8000, # Antall dager forlengelse på hver side
line.width = 5, # Tykkelse på tidslinjen
line.color = "darkgreen", # Farge på tidslinjen
scale = "20 years", # Intervaller langs tidslinjen
scale.cex = 1, # Fontstørrelsen på årstallene langs tidslinjen
scale.tickwidth = 3, # Tykkelsen på de vertikale taggene
labels = paste(df_slag[[1]]), # Hvilke data som skal utgjøre teksten
label.color = "orange", # Farge på linjen mellom hovedlinjen og titlene
label.cex = 1,
point.color = "red", # Farge på punktmarkøren
)
dev.off()Ifølge dokumentasjonen til pakken timelineS kan vi gjøre flere andre typer justeringer. Vi kan for eksempel endre tekstens font, farge og vinkel, justere lengden på hver enkel av de vertikale linjene og bestemme hva som skal være over og under hovedlinjen. Når dette er sagt, er vi fortsatt ganske låst til de overordnede designvalgene til utvikleren av timelineS. For å få full kontroll over utseendet til tidslinjen, må vi lage den fra bunnen med ggplot2.
ggplot2Å lage tidslinje i ggplot2 er litt mer arbeid, men til gjengjeld gir det betydelig større muligheter for tilpasninger. Vi kan prøve å lage en variant av den samme tidslinjen. Her er det viktig å laste inn datarammen på nytt, fordi vi endret på en av variablene (df_slag$år) i forrige del. Hvis du ikke gjør dette, vil du få feilmelding nedenfor.
df_slag <- read.csv("slag.csv")Enkelt fortalt involverer prosessen fem steg. Steg 1 er å tegne opp en enkel linje midt på lerretet. Som med alt annet i ggplot2, må vi tenke på lerretet som et koordinatsystem med en x- og en y-akse. Vi står fritt til å definere hva verdiene på disse aksene skal være, så det første vi må gjøre er å bestemme oss for hva yttergrensene på aksene skal være. Siden x-aksen skal bestå av årstall, velger vi et startpunkt som er litt før det laveste årstallet og et sluttpunkt som er litt etter det høyeste årstallet, for eksempel slik:
start <- 800
slutt <- 1100Y-aksen, derimot, henger sammen med lengden på de vertikale strekene eller stolpene som skal markere hendelser. Hvilke verdier du setter på y-aksen avhenger av hvor mye variasjon du ser for deg å ha på lengden av disse stolpene. Vi skal bare ha to ulike lengder over og under linjen. I tillegg vil vi ha litt luft over og under, så vi kan tenke at vi skal ha tre nivåer over og under. Vi definerer derfor en variabel som er delelig med tre og kaller den makshøyde. Vi bruker tallet 3 slik at vi får runde tall (1 og 2) når vi skal sette lengden på stolpene.
makshøyde <- 3Nå kan vi tegne opp lerretet og en enkel linje. For å lage linjen bruker vi geom_segment(), som tar parametrene x og y for punktet hvor linjen starter og xend og yend for punktet hvor linjen slutter. Siden linjen skal gå rett horisontalt, setter vi verdien 0 for både y og yend. For x og xend bruker vi variablene start og slutt som vi nettopp laget. I tillegg legger vi inn parametere for tykkelse og farge på linjen, samt litt kode for å få pilspisser i hver ende.
For å tegne y-aksen, bruker vi funksjonen scale_y_continuous() og parameteret limits (se Figur 4). Vi vil at y-aksen skal gå til 3 over linjen og til -3 under linjen, og siden vi har lagret tallet 3 i variabelen makshøyde kan vi bruke den når vi setter verdien limits (vi bare setter et minustegn foran for å få -3). Vi lagrer denne første opptegningen i objektet linje fordi vi skal bygge videre på det etterpå.
if (!require("ggplot2")) install.packages("ggplot2")
library(ggplot2)
linje <- ggplot() +
geom_segment(
aes(
x = start,
xend = slutt,
y = 0,
yend = 0
),
linewidth = 1,
color = "purple",
arrow = arrow(ends = "both", length = unit(0.3, "cm"))
) +
scale_y_continuous(limits = c(-makshøyde, makshøyde))
linje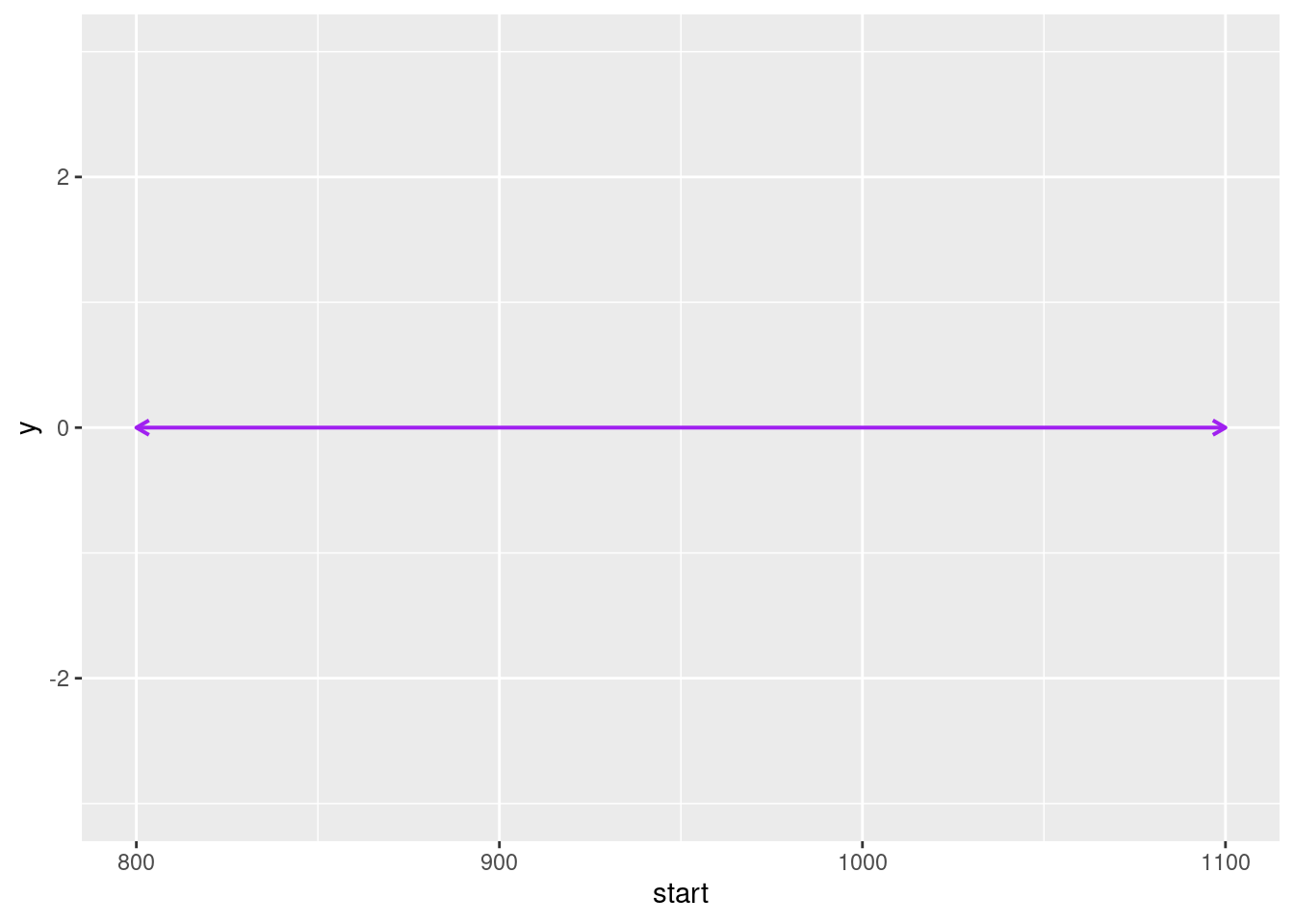
ggplot().
Steg to er å tegne årstall på linjen og lage små merker eller horisontale tagger for hvert av tallene. Her må vi lage en oss en tallserie med intervaller som samsvarer med avstanden vi ønsker å ha mellom hvert årstall. Vi kan gjøre som i forrige tidslinje og ha 20 år mellom hvert årstall. For å lage tallserien kan vi bruke funksjonen seq(), som tar tre argumenter: første tall, siste tall, og lengden på intervallet. Vi vil imidlertid ikke ha merke på ytterpunktene, for der er det pilspiss, så vi starter i 820 og slutter i 1080.
merker <- seq(start + 20, slutt -20, 20)For å tegne på årstallene, bruker vi funksjonen annotate(), som vi ble introdusert for i forrige kapittel. Når vi skal bruke annotate() til å tegne på tekst, er det tre hovedparametere som gjelder: x og y for stedet hvor teksten skal stå og label for selve teksten som skal påtegnes. Så er det slik at ggplot2-funksjoner som annotate() kan brukes til å sette inn mange ting på én gang, så lenge vi setter inn vektorer som verdier for de aktuelle parametrene. Vi kan derfor sette inn alle tallene i vektoren merker ved å oppgi den som verdi for parameteret label. Siden disse tallene også tilsvarer stedene langs x-aksen hvor tallene skal stå, kan vi bruke merker som verdi for parameteret x. Vi vil ha tallene bittelitt under linjen, så vi setter y til et lavt negativt tall.
For å tegne opp merkene langs linjen, bruker vi igjen geom_segment() (se Figur 5). Denne gangen går strekene vertikalt, så verdiene for x og xend skal være de samme, mens verdiene for y og yend må være forskjellige. For å få en liten strek på alle x-verdiene i merker, putter vi bare objektet merker inn som verdi for x og xend. Vi setter y til 0 og yend til et lavt negativt tall ettersom strekene bare skal være en millimeter eller to lange.
tallinje <- linje +
annotate(geom = "text",
x = merker,
y = -.2,
label = merker,
size = 5) +
geom_segment(aes(x = merker,
xend = merker,
y = 0,
yend = -.08
),
linewidth = 1,
color = "purple"
)
tallinje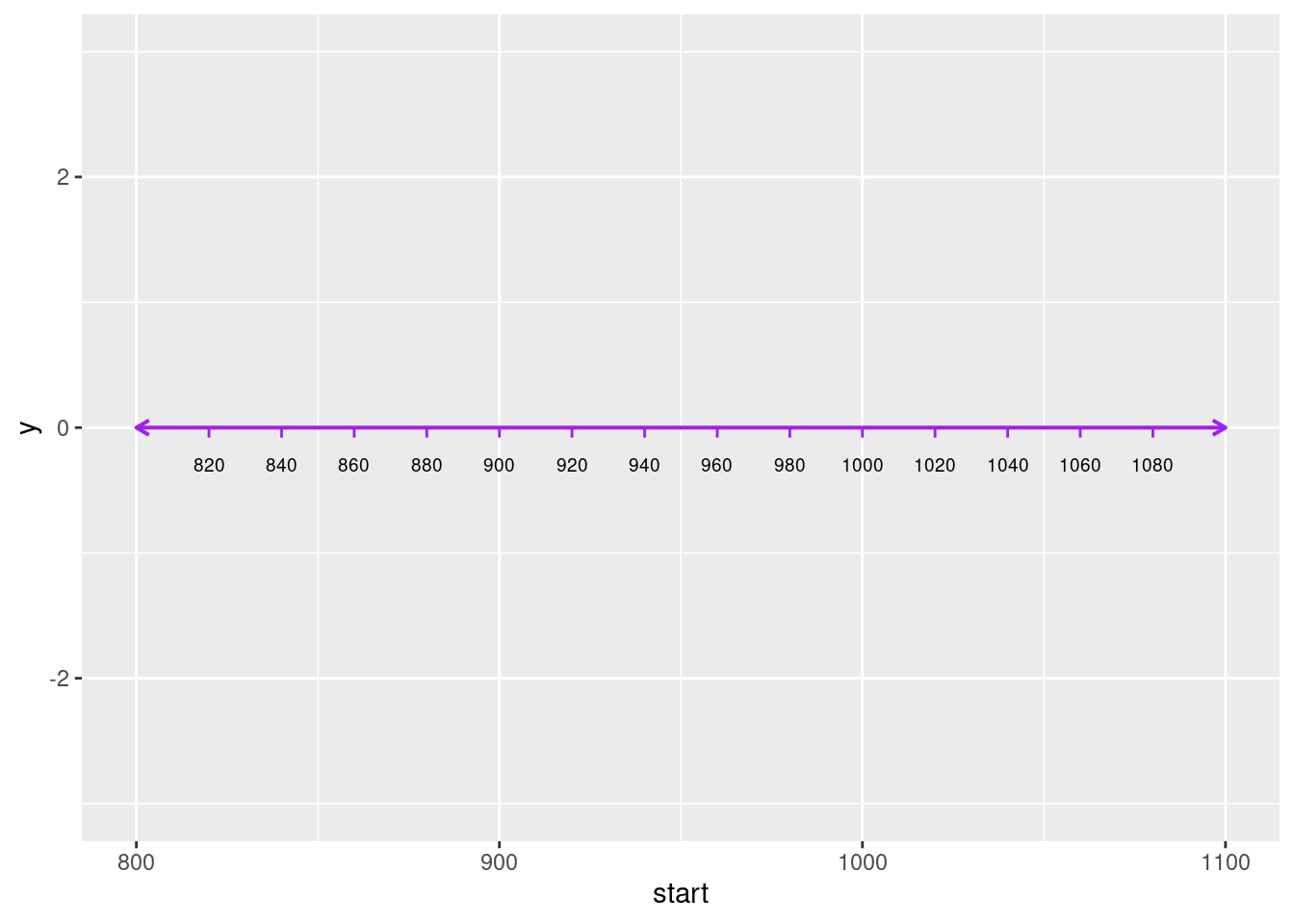
ggplot().
Steg tre er å tegne opp stolpene som skal gå fra hovedlinjen og ut til hendelsesbeskrivelsene. For å tegne disse må vi lage en vektor med tall som spesifiserer hvor langt ut fra hovedlinjen hver vertikale linje skal gå. Denne vektoren, som vi kan kalle høyde, må ha like mange verdier som det er hendelser som skal påtegnes. Verdiene må være mindre enn yttergrensene på y-aksen, altså mindre enn tallet vi satte som makshøyde, dvs 3. Nøyaktig hvilke verdier du velger, avhenger av hvor du vil ha lave og høye stolper. Her kan du prøve deg litt fram, men vi tester med følgende tallserie.
høyder <- c(1, -1, 2, -2, 1, -1)Vi bruker så disse verdiene inn i geom_segment() en gang til. De går inn som verdier i parameteret yend slik at vi får vertikale streker fra hovedlinjen (y = 0) ut til høydene vi har satt (se Figur 6). For å få strekene på riktig sted langs x-aksen, bruker vi årstallene i kolonnen df_slag$år som verdier for x og xend. Vi vil også ha sirkler der de vertikale strekene møter hovedlinjen; til dette bruker vi geom_point() med df_slag$år som verdier for x.
stolper <- tallinje +
geom_segment(aes(y = 0,
yend = høyder,
x = df_slag$år,
xend = df_slag$år
),
linewidth = .3) +
geom_point(aes(x = df_slag$år, y = 0), size = 2)
stolper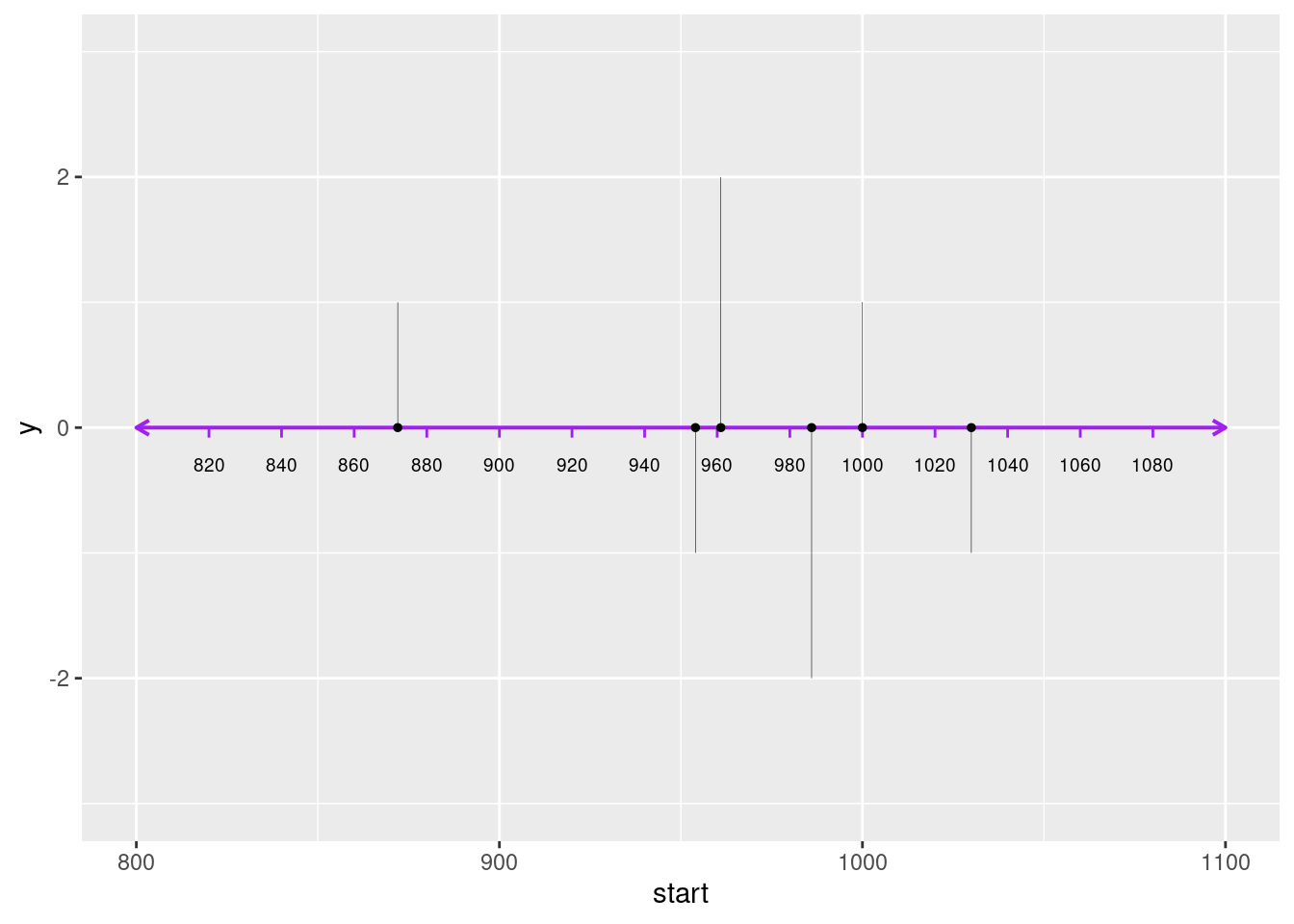
ggplot().
Steg fire er å sette på hendelsesbeskrivelsene (se Figur 7). Til dette bruker vi igjen funksjonen annotate(). Den trenger som nevnt x- og y-verdier for å vite hvor den skal plassere teksten. x-verdiene er de samme som for stolpene, altså vektoren df_slag$år. y-verdiene er de samme som høydene på stolpene, altså vektoren høyder. For et litt mer fancy utseende kan vi bruke geom = "label" i stedet for geom = "text"; dette gir oss tekstbokser rundt teksten.
For selve beskrivelsene kan vi også gjøre litt mer ut av det ved å legge til det nøyaktige årstallet for hver hendelse under teksten. Her bruker vi bare paste0() til å lime tekstene sammen med årstallene, med \n i mellom. Vi lagrer de nye beskrivelsene i en ny vektor som vi så oppgir i parameteret label i annotate().
beskrivelser <- paste0(df_slag$navn, "\n", df_slag$år)tekst <- stolper +
annotate(geom = "label",
x = df_slag$år,
y = høyder,
label = beskrivelser,
size = 4,
label.padding = unit(0.3, "cm"),
fill = "wheat")
tekst
ggplot().
Femte og siste steg er finpussen. Nå kan vi fjerne rutenettet og aksene, legge på tittel og fargelegge bakgrunnen. Vi sentrerer tittelen og gir den større font med hjelpefunksjonene easy_center_title() og easy_plot_title_size() fra pakken ggeasy (se Figur 8}).
if (!require("ggeasy")) install.packages("ggeasy")
library(ggeasy)
tekst +
theme_void() +
labs(title = "\nKjente slag i vikingtiden") +
easy_center_title() +
easy_plot_title_size(30) +
theme(plot.background = element_rect(fill = "lightblue"))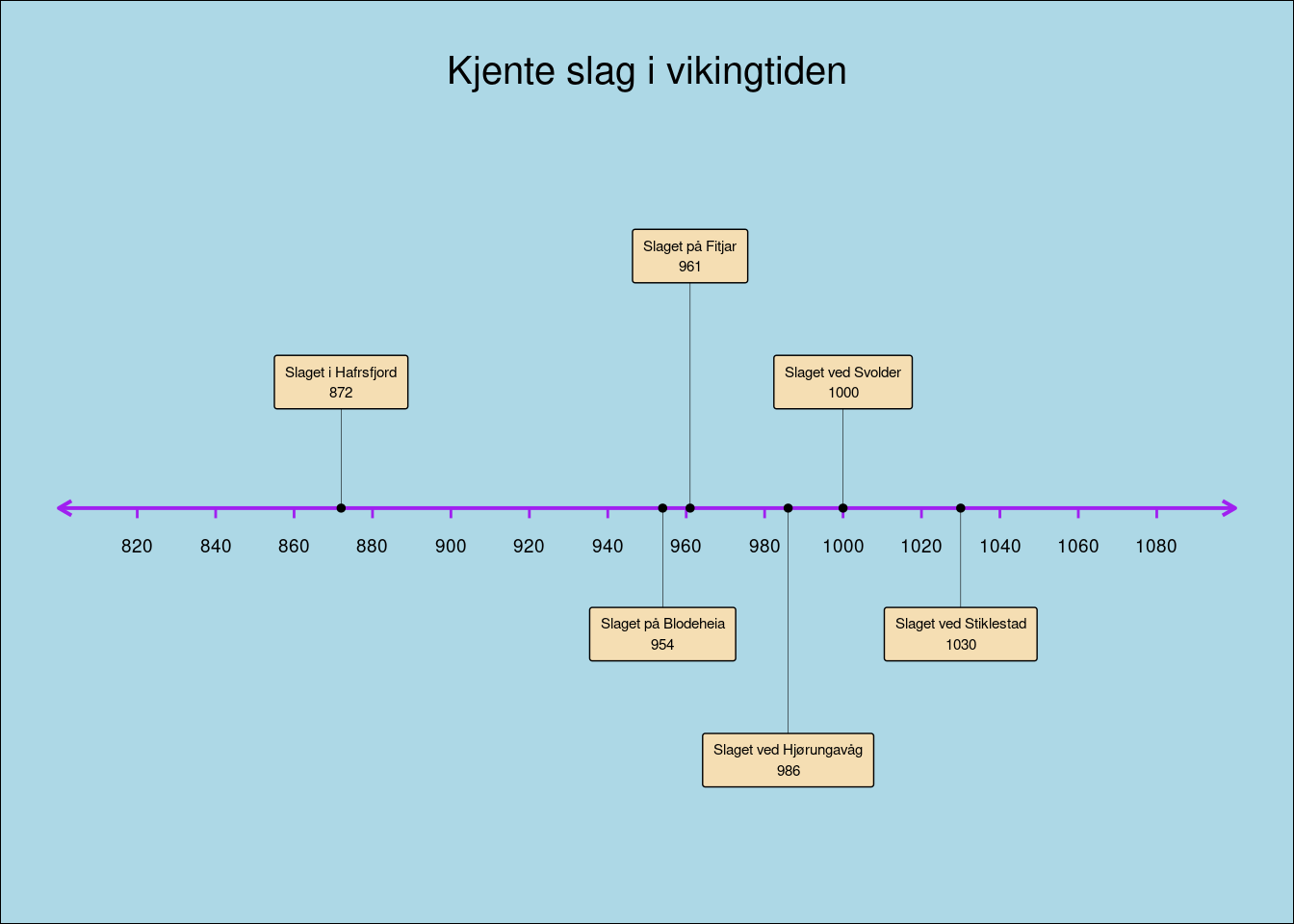
ggplot().
Dette er kanskje ikke verdens mest avanserte tidslinje, men nå som vi vet hvordan tidslinjen er bygget opp, er det mye lettere å eksperimentere med andre estetiske uttrykk.
Som et eksempel kan vi prøve å lage en variant av samme tidslinje, denne gangen med bilder. Vi går tilbake et par steg og bygge videre på grafobjektet stolper, som inneholder tidslinjen og stolpene, uten tekstbeskrivelser. Vi kan sette inn bilder i stedet for beskrivelser ved å bruke funksjonen geom_image() fra pakken ggimage. Den trenger bare x- og y-verdier for de stedene hvor bildene skal settes inn, samt en verdi for parameteret image. Dette kan være en vektor med søkestier til bildefiler på harddisken din eller lenker til bilder et sted på nettet. Her får vi endelig bruk for lenkene i datarammen df_slag; vi putter bare vektoren df_slag$bilde inn som verdi for parameteret image. Og vips har vi en tidslinje med et kunstverk for hvert av slagene (se Figur 9).1
if (!require("ggimage")) install.packages("ggimage")Loading required package: ggimagelibrary(ggimage)
bilder <- stolper +
geom_image(
aes(
x = df_slag$år,
y = høyder,
image = df_slag$bilde
),
size = .2
)
bilder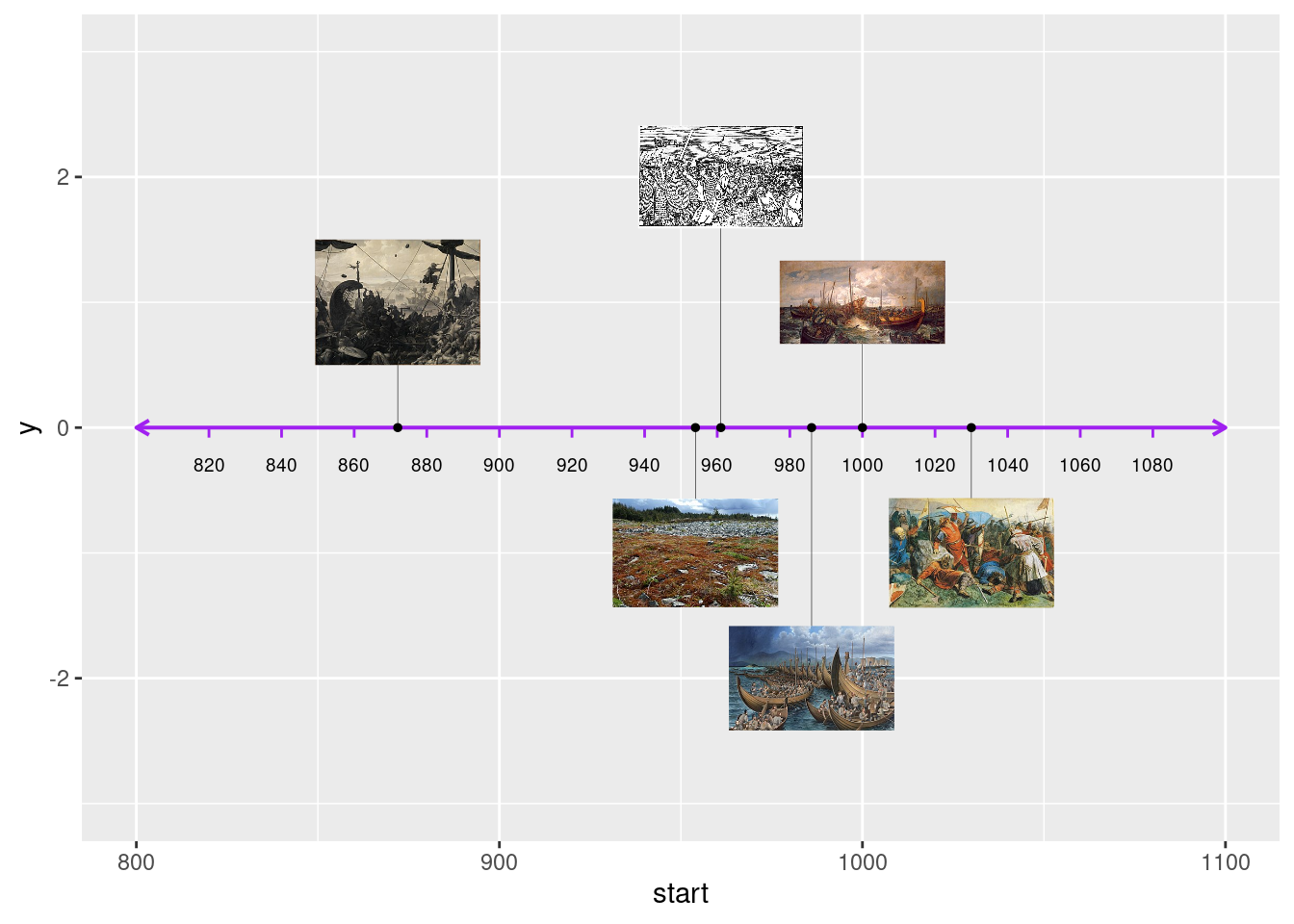
ggplot() — med bilder.
På nytt bør vi finpusse ved å fjerne rutenettet og legge på farger. I tillegg må vi anerkjenne opphavet til bildene. Det er lett å gjøre ettersom kunstnernavnene er lagret i datarammen df_slag. Vi bruker paste() til å bygge en streng som kan fungere som opphavsnotis.
opphav <- paste("Kunstnere: \n",
paste(df_slag$kunstner, collapse = "\n")
)Deretter benytter vi samme kode som sist, men vi legger til funksjonen annotate() og plasserer opphavsteksten nede til venstre på figuren ved hjelp av parametrene x og y (se Figur 10).
bilder +
theme_void() +
labs(title = "\nKjente slag i vikingtiden") +
easy_center_title() +
easy_plot_title_size(30) +
theme(plot.background = element_rect(fill = "mistyrose")) +
annotate(geom = "text",
x = 840,
y = -1.7,
label = opphav,
size = 5)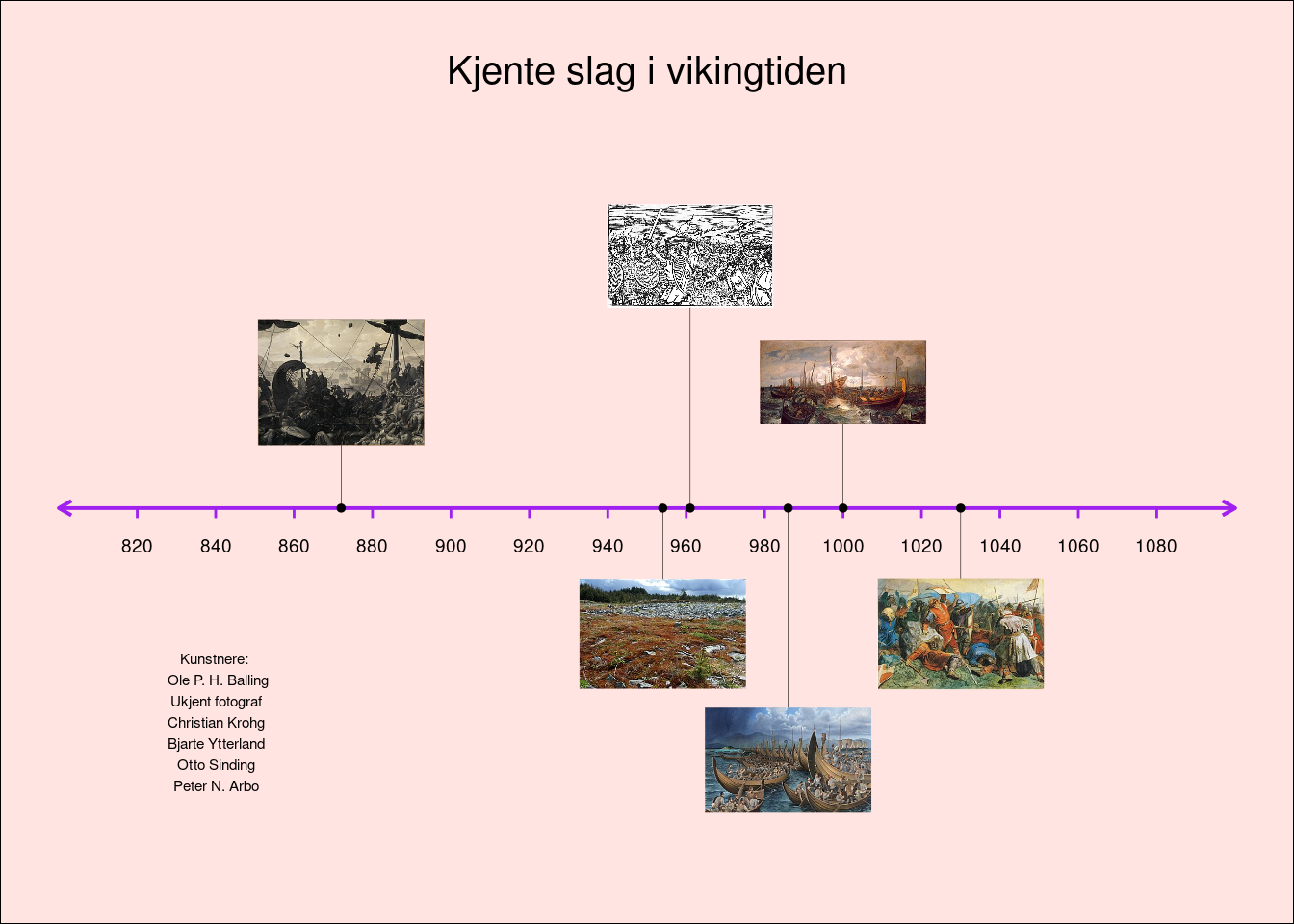
ggplot() — med bilder og tilpasninger.
ggplot2En av tidslinjens nærmeste slektninger er Gantt-diagrammet. Du kjenner det fra søknader og prosjektbeskrivelser: horisontale og delvis overlappende søyler som viser når ulike faser i prosjektet er ment å være ferdig. Men Gantt-diagrammer kan brukes til mye annet, for eksempel til historieformidling. I det følgende skal vi lage et diagram som viser når og hvor lenge de første norske vikingkongene levde.
Det er flere måter å lage Gantt-diagrammer på i R, men den mest fleksible og robuste er med ggplot2.2 Til dette trenger vi en dataramme som er formatert på en hensiktsmessig måte. Ettersom kjernen i Gantt-diagrammer er tidsperioder, trenger vi en dataramme med minst tre kolonner: 1) navnet på periodene, 2) startpunktene og 3) sluttpunktene. Overført til vårt eksempel trenger vi altså en dataramme med navnet på kongene, deres fødselsår og deres dødsår.
I bokens dataarkiv ligger det en fil kalt “kap06_konger.csv” med navn, estimert fødselsår og dødsår på syv konger fra Harald Hårfagre til Olav Haraldsson. Vi kan laste den ned med hent_data() og inn i R med read.csv().
hent_data("kap06_konger.csv")Laster ned 'kap06_konger.csv' til /home/thomas/repos/github/rforalle_net ..df_konger <- read.csv("konger.csv")Igjen inspiserer vi med str() og head() for å være sikre på at vi har riktige data.
str(df_konger)
head(df_konger)Nå kan opptegningen begynne. Planen er å få en horisontal søyle for hver av kongene, og denne søylen skal starte ved fødselsåret og slutte ved dødsåret. I sluttversjonen skal x-aksen derfor ha årstall, mens y-aksen skal ha kongenavnene. For å lage søyler kan vi bruke funksjonen geom_segment(), som vi brukte en del når vi laget tidslinje. Vi husker at geom_segment() trenger fire parametere: x, xend, y og yend.
Forskjellen denne gangen er at den ene variabelen (“år”) består av tall, mens den andre (“navn”) består av tekst. I et koordinatsystem vil de oppføre seg annerledes, fordi en tekstvariabel ikke har en åpenbar matematisk rekkefølge, mens en tallvariabel har det. I forbindelse med grafer kaller man tallvariabler for kontinuerlige variabler (eng. continuous variables) og tekstvariabler for diskrete variabler (eng. discrete variables). Du kan også tenke på diskrete variabler som kategorier.
Når vi har en kombinasjon av diskrete og kontinuerlige variabler slik som her, er det god praksis å starte med å knytte den diskrete variabelen til x-aksen og den kontinuerlige til y-aksen selv om vi til slutt skal ha det omvendt. Det er fordi ggplot2 i noen tilfeller kan oppføre seg rart hvis y-variabelen ikke er kontinuerlig.
Vi starter derfor med å knytte x-parametrene i geom_segment() til df_konger$navn og y-parametrene til henholdsvis df_konger$født og df_konger$død som følger (se Figur 11).
library(ggplot2)
ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død))
ggplot().
Men vi ville jo ha navnene på venstre side, altså på y-aksen. For å få det til, brker vi den fiffige funksjonen coord_flip() som bytter om på x og y aksen slik at figuren fremstår som vridd 90 grader (se Figur 12).
ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død)) +
coord_flip()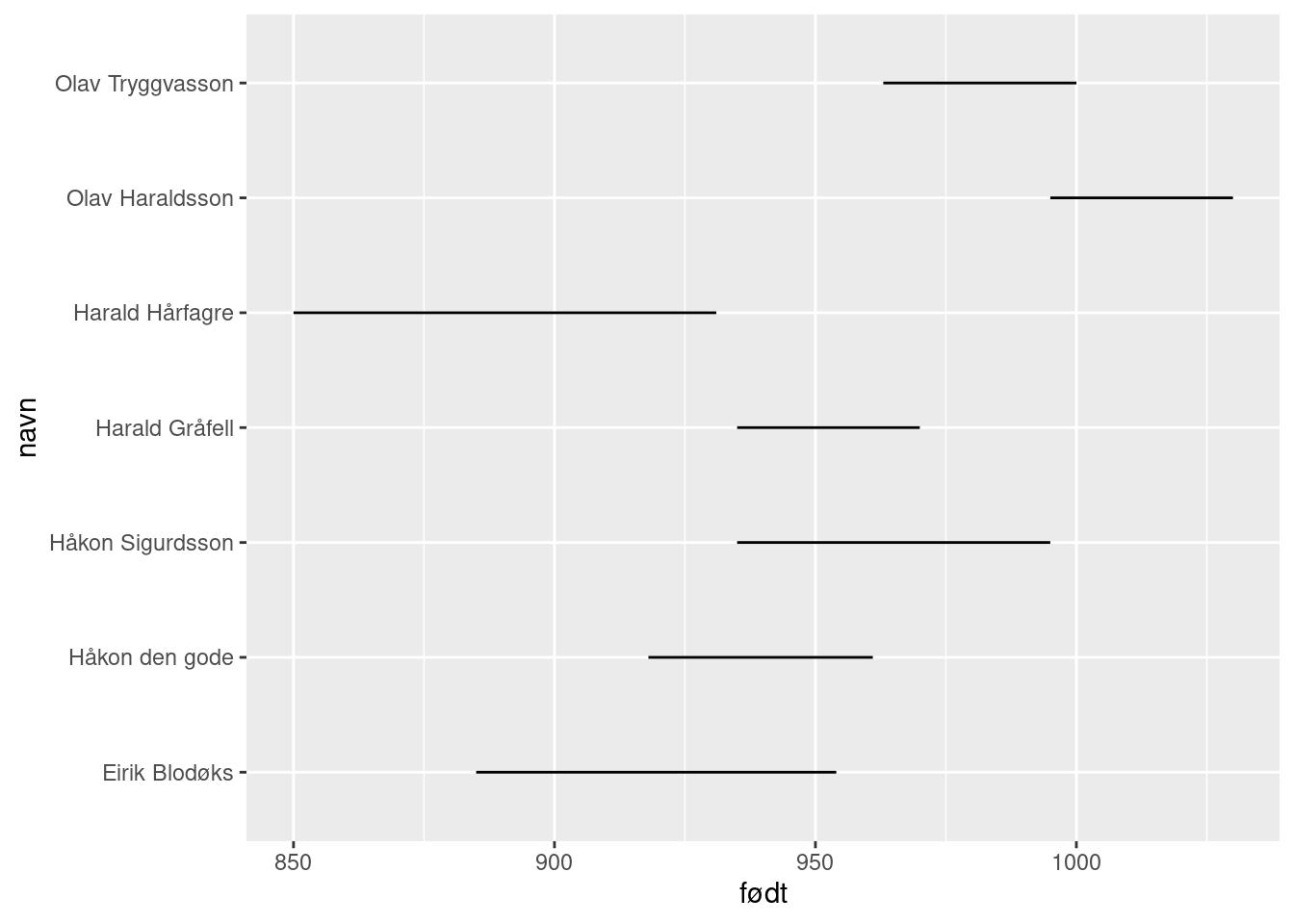
ggplot().
Vi er på rett spor, men mye gjenstår. Vi ser blant annet at navnene er stokket om; R har satt dem i alfabetisk rekkefølge etter fornavn, nedenfra og opp. Dette er noe ggplot2 gjør automatisk med tekstvektorer, og for å unngå det må vi gjøre strengene i vektoren om til det som kalles “faktorer”, det vil si kategorier som ikke kan flyttes på. Dette gjøres enklest med funksjonen fct_inorder() fra pakken forcats. Den “fryser” rekkefølgen til en vektor slik den står i den opprinnelige datarammen. Vi skal komme nærmere tilbake til temaet faktorer i kapittel 11.
if (!require("forcats")) install.packages("forcats")Loading required package: forcatslibrary(forcats)
df_konger$navn <- fct_inorder(df_konger$navn)Hvis vi nå kjører samme kommando som tidligere, er navnene i riktig rekkefølge (se Figur 13):
ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død)) +
coord_flip()
ggplot() — med navn i endret rekkefølge.
Kanskje er det mest logisk å ha den første kongen øverst. La oss derfor snu om på rekkefølgen i navneaksen. ggplot2 har et sett med funksjoner som lar oss manipulere akser; vi brukte to av dem — scale_x_continuous() scale_y_continuous() — i forrige kapittel. For diskrete variabler slik som kongenavnene våre må vi bruke scale_x_discrete() eller scale_y_discrete(). Siden vi knyttet navnene til x-verdiene, bruker vi scale_x_discrete(). For å snu om på rekkefølgen i verdiene (altså navnene) setter vi uttrykket limits = rev (for reverse) mellom parentesene. (se Figur 14):
ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død)) +
coord_flip() +
scale_x_discrete(limits = rev)
ggplot() — med navn i snudd rekkefølge.
Så må vi endre linjene/søylene, og det gjør vi med parametere inni geom_segment(). Vi kan øke bredden med linewidth og endre fargen med color (se Figur 15).
gantt_farger <- ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død),
linewidth = 10,
color = "purple") +
coord_flip() +
scale_x_discrete(limits = rev)
gantt_farger
ggplot() — med modifiserte søyler.
Finpussen gjenstår. Vi bør blant annet legge til hovedtittel og fjerne aksetitlene med funksjonen labs(). Vi kan også gjøre x-aksen om til en tydelig tidslinje. Det gjør vi med funksjonen theme() og diverse parametere som starter med axis.*. Vi trenger ikke gå inn på detaljene her; bare noter at hver minste detalj ved plottet kan justeres.3 Til slutt kan vi endre bakgrunnsfargen og rutenettet med parametere som starter med panel.* inni theme(). La oss se hvordan dette blir (se Figur 16):
gantt_ferdig <- gantt_farger +
labs(title = "Når levde de første norske kongene?", x = "", y = "") +
theme(axis.line.x = element_line(linewidth = 1),
axis.text.x = element_text(size = 10, face = "bold"),
axis.ticks.x = element_line(linewidth = .5),
axis.ticks.length.x = unit(.5, "cm"),
panel.background = element_rect(fill = "lavenderblush2"),
panel.grid.major.x = element_line(color = "grey80"),
panel.grid.minor.x = element_line(color = "grey80"),
panel.grid.major.y = element_blank()
)
gantt_ferdig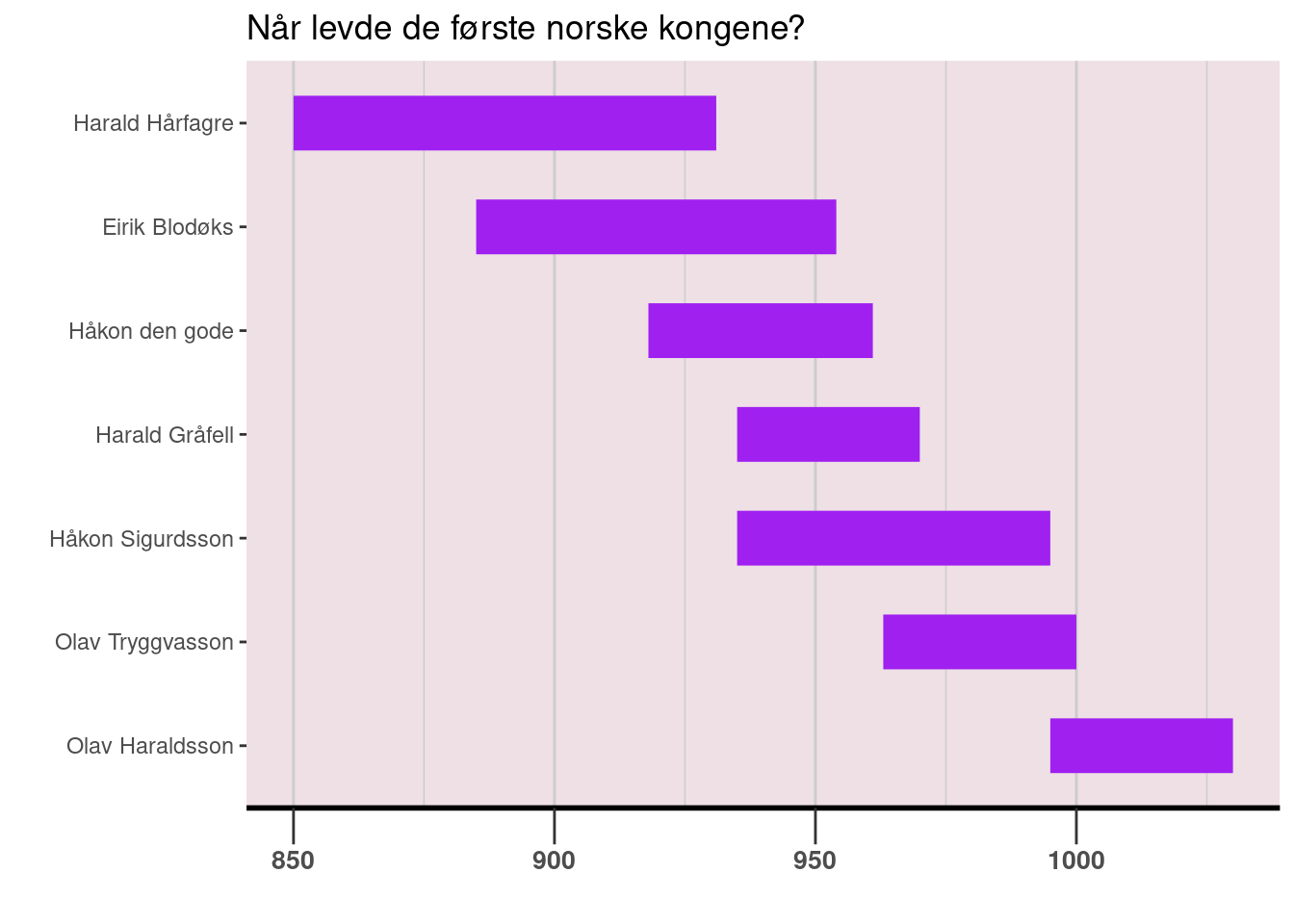
ggplot() — med endret bakgrunn og akse.
Vi kan også prøve å lage en litt annen variant hvor navnene står inni søylene og ikke i en liste til venstre. Det kan vi få til med funksjonen annotate(), som plasserer det man vil hvor man vil på figuren. Men for å få navnene midt i de brune feltene, må vi lage en ny vektor med verdier for sentrum av hvert segment. Det er ren matematikk og kan formuleres slik:
df_konger$midten <- df_konger$født + (df_konger$død - df_konger$født) / 2La oss inspisere datarammen for å se om det ble riktig:
df_konger navn født død midten
1 Harald Hårfagre 850 931 890.5
2 Eirik Blodøks 885 954 919.5
3 Håkon den gode 918 961 939.5
4 Harald Gråfell 935 970 952.5
5 Håkon Sigurdsson 935 995 965.0
6 Olav Tryggvasson 963 1000 981.5
7 Olav Haraldsson 995 1030 1012.5Da kan vi plotte inn navnene med annotate() samt fjerne navnene fra y-aksen med noen ekstraparametere i theme() (se Figur 17). Vi bør også endre fargen på søylene slik at teksten blir synlig. Vi kan også endre fargen på borden rundt plottet med parameteret plot.background i theme(). Vi kan rekapitulere og ta med koden helt fra start.
ggplot(data = df_konger) +
geom_segment(aes(x = navn, xend = navn, y = født, yend = død),
linewidth = 10,
color = "darkgoldenrod1") +
coord_flip() +
scale_x_discrete(limits = rev) +
annotate(geom = "text",
x = df_konger$navn,
y = df_konger$midten,
label = df_konger$navn,
color = "black",
fontface = "bold",
size = 2) +
labs(title = "Når levde de første norske kongene?", x = "", y = "") +
theme(axis.line.x = element_line(linewidth = 1),
axis.text.x = element_text(size = 10, face = "bold"),
axis.ticks.x = element_line(linewidth = .5),
axis.ticks.length.x = unit(.5, "cm"),
panel.background = element_rect(fill = "grey95"),
panel.grid.major.x = element_line(color = "grey80"),
panel.grid.minor.x = element_line(color = "grey80"),
panel.grid.major.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.background = element_rect(fill = "wheat"),
)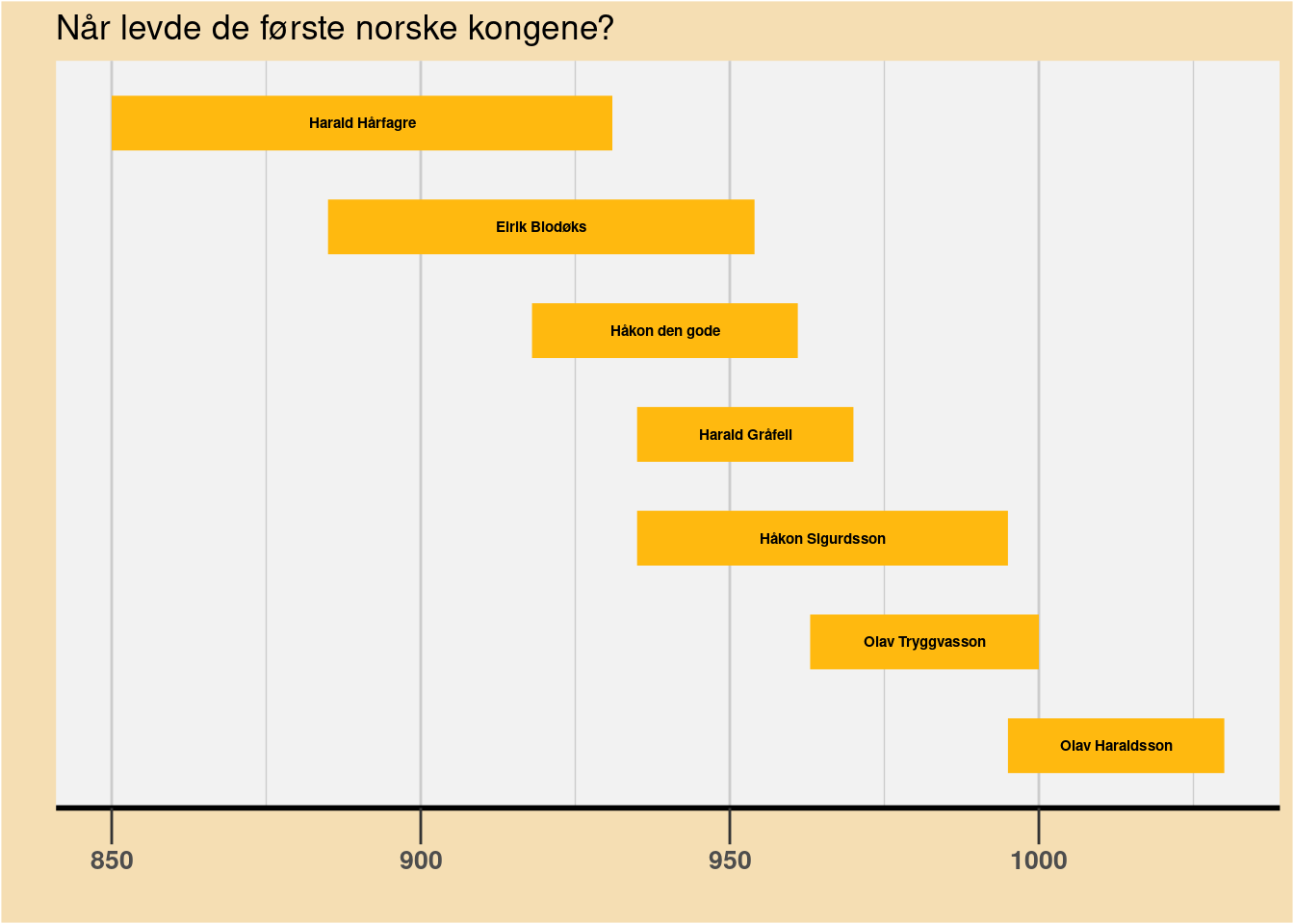
ggplot() — med annoteringer.
Ikke fortvil hvis dette virker komplisert. Det tar tid å lære seg hvilke kommandoer som endrer hva i ggplot2 og ikke minst hva alle parametrene som kan settes inn i theme() heter. Men når du får det inn i fingrene, har du et svært nyttig verktøy til disposisjon.
ggraphHittil har vi jobbet mest med grafer og diagrammer som representerer noe kronologisk. En annen viktig kategori diagrammer beskriver relasjoner mellom ting, for eksempel genetiske relasjoner, konseptuelle sammenhenger, prosesser eller nettverk.
La oss si vi ville lage et slektstre som viser hvordan de tidlige norske vikingkongene sto i slektsmessig forhold til hverandre. Til dette kan vi bruke et såkalt dendrogram, som det er god støtte for i R, blant annet fordi mange biologer bruker R.
Dendrogrammer kan lages på flere måter, men vi skal bruke pakken ggraph, som er en generell verktøykasse for fremstilling av relasjonsdata. ggraph har den fordelen at den bruker omtrent samme syntaks som ggplot2, så vi slipper å lære enda en ny måte å lage figurer på.
Her igjen er det struktureringen av datarammen som er det vanskeligste. For å lage dendrogram med ggraph må vi ha en dataramme bestående av rader som representerer parvise relasjoner — det som i nettverksanalyse kalles “kanter” (eng. edges). En kant består av to “noder”; én i hver ende av kanten. Datarammen må derfor ha to kolonner, én for startnoden og én for sluttnoden. Disse kolonnene må ha navnet “from” og “to” for at ggraph skal kunne lese datarammen.
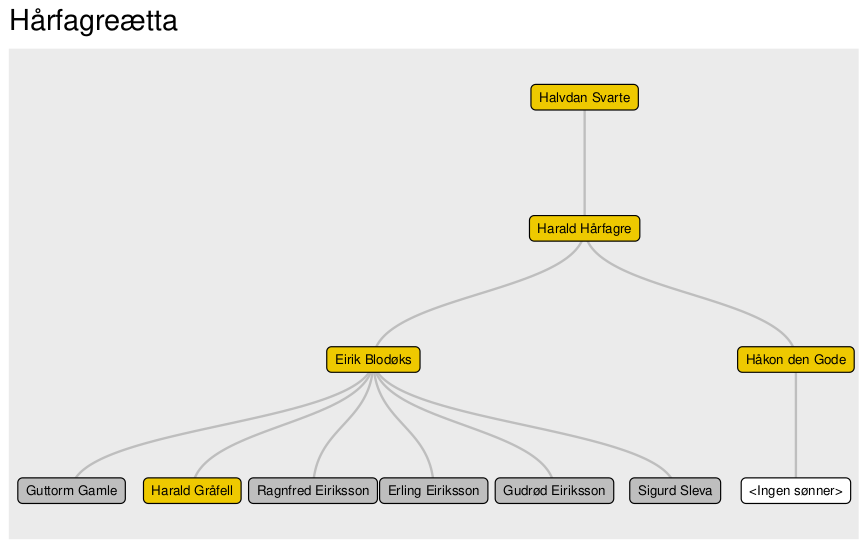
I bokens dataarkiv ligger det en CSV-fil kalt “kap06_slekt.csv” som er ferdig formatert til dette formålet. Datarammen inneholder relasjondata fra den såkalte Hårfagreætta, nærmere bestemt de fire generasjonene fra Halvdan Svarte via Harald Hårfagre ned til sistnevntes barnebarn. Det er langt fra en komplett fremstilling, for av Harald Hårfagres over 20 barn har jeg bare tatt med Eirik Blodøks og Håkon den Gode, siden det var de som fikk kongemakt.
La oss laste ned filen med hent_data() og se hvordan en relasjonsdataramme ser ut inni.
hent_data("kap06_slekt.csv")Laster ned 'kap06_slekt.csv' til /home/thomas/repos/github/rforalle_net ..df_rel <- read.csv("slekt.csv")
df_rel from to
1 Halvdan Svarte Harald Hårfagre
2 Harald Hårfagre Eirik Blodøks
3 Harald Hårfagre Håkon den gode
4 Eirik Blodøks Guttorm Gamle
5 Eirik Blodøks Harald Gråfell
6 Eirik Blodøks Ragnfred Eiriksson
7 Eirik Blodøks Erling Eiriksson
8 Eirik Blodøks Gudrød Eiriksson
9 Eirik Blodøks Sigurd Sleva
10 Håkon den gode <Ingen sønner>Her har vi altså ti rader, en for hver kant (dvs. bilaterale relasjon).
Nøkkelfunksjonen i pakken ggraph heter simpelthen ggraph(), og den tar en dataramme som hovedargument. I likhet med ggplot() genererer ikke ggraph() alene noen figur; vi må plusse på en geom_*-funksjon som spesifiserer hvilken grafikk vi ønsker. I ggraph-systemet heter disse funksjonene som oftest noe med geom_edge_* og geom_node_*. Vi skal bruke geom_edge_diagonal(), som tegner avrundete streker mellom nodene (se Figur 18).
if (!require("ggraph")) install.packages("ggraph")Loading required package: ggraphlibrary(ggraph)
ggraph(df_rel, layout = "auto") +
geom_edge_diagonal()Using "tree" as default layout
ggraph().
Vi ser at ggraph() og geom_edge_diagonal() gir oss diagrammets skjelett — altså forbindelsene mellom nodene uten nodenes navn. For å vise navnene må vi plusse på enten geom_node_text() eller geom_node_label(). Den første legger bare til tekst, den andre legger til tekst med en tekstboks rundt. Vi må også fortelle R hvor disse funksjonene skal hente teksten fra, og det gjør vi ved å sette uttrykket aes(label = name) mellom parentesene (se Figur 19). Vi kan også justere fontstørrelse, skriftstørrelse og andre ting med parametere inni geom_node_label(). Vi setter size = 2 for at ikke boksene skal overlappe.
ggraph(df_rel, layout = "auto") +
geom_edge_diagonal() +
geom_node_label(aes(label = name), size = 2)Using "tree" as default layout
ggraph() — med tekstbokser.
Vi vil også ha mer luft rundt diagrammet slik at alt kommer med. Det gjør vi med funksjonene scale_x_continuous() og scale_y_continuous() og parameteret limits. Men hva skal yttergrensene være? Vi ser at diagrammet vårt er syv noder bredt og fire noder høyt, noe som betyr at x-koordinatene i utgangspunktet går fra 0 til 6 og y-koordinatene går fra 0 til 3. Hvis vi tar en noe lavere minimumsverdi og litt høyere maksverdi, vil “lerretet” bli større. Vi kan også legge til en tittel med funksjonen labs() (se Figur 20).
ggraph(df_rel, layout = "dendrogram") +
geom_edge_diagonal() +
geom_node_label(aes(label = name), size = 2) +
scale_x_continuous(limits = c(-0.2,6.2)) +
scale_y_continuous(limits = c(-0.2,3.2)) +
labs(title = "Hårfagreætta")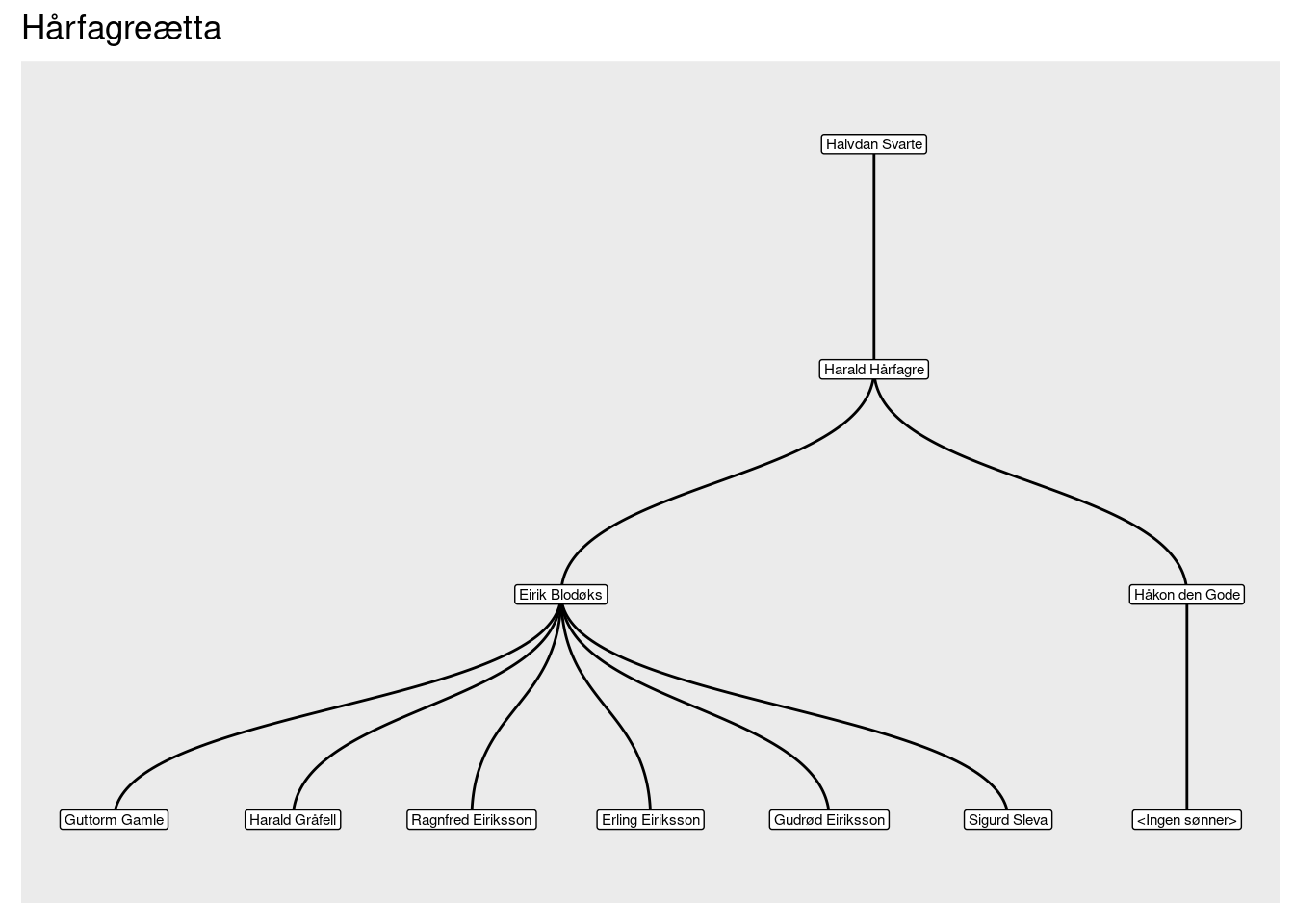
ggraph() — med ryddige tekstbokser.
Og vips har vi et ferdig trediagram. Det er mye mer vi kan gjøre, for de fleste funksjonene som modifiserer ggplot-figurer fungerer også på ggraph-figurer, så jo mer du lærer om ggplot, jo lettere vil det bli å finpusse ggraph-diagrammer.
For læringens skyld kan vi gjøre ytterligere et par justeringer. Det ene er å endre farge og tykkelse på linjen mellom nodene. Det gjør vi med parametrene width og color inni funksjonen geom_edge_diagonal().
Det andre er å fargelegge tekstboksene selektivt for å skille mellom de som ble konger og de som ikke ble det. Her må vi bruke parameteret fill inni geom_node_label(). Å få samme farge på alle tekstboksene er lett; det er bare å sette fill til én bestemt farge (f. eks. fill = "grey"). Å få forskjellige farger er litt mer krevende. Da må vi lage en vektor med fargekoder — én for hver tekstboks — og så oppgi denne vektoren som verdi til parameteret fill.
For at dette skal fungere, må hver tekstboks være representert i vektoren med hver sin tiltenkte fargekode. Vi må også vite at R begynner å telle ovenfra og teller fra venstre mot høyre, så det første elementet i vektoren representerer noden Halvdan Svarte, den fjerde representerer Håkon den Gode, osv. Vi vet at bare de fire første samt Harald Gråfell ble konger, så vi gir disse en egen farge.
farger <- c("gold2", "gold2", "gold2", "gold2", "grey", "gold2", "grey", "grey", "grey", "grey", "white")Nå kan vi tegne opp diagrammet (se Figur 21):
ggraph(df_rel, layout = "dendrogram") +
geom_edge_diagonal(width = 0.5, color = "grey") +
geom_node_label(aes(label = name),
size = 2,
fill = farger) +
scale_x_continuous(limits = c(-0.2,6.2)) +
scale_y_continuous(limits = c(-0.2,3.2)) +
labs(title = "Hårfagreætta")
ggraph() — med fargede bokser.
Før vi går videre kan vi ta en rask titt på hvor lett det er å endre diagramstruktur i ggraph. For å snu diagrammet opp-ned, kan vi endre layout-parameteret i ggraph()-funksjonen fra “dendrogram” til “partition” (se Figur 22):
ggraph(df_rel, layout = "partition") +
geom_edge_diagonal()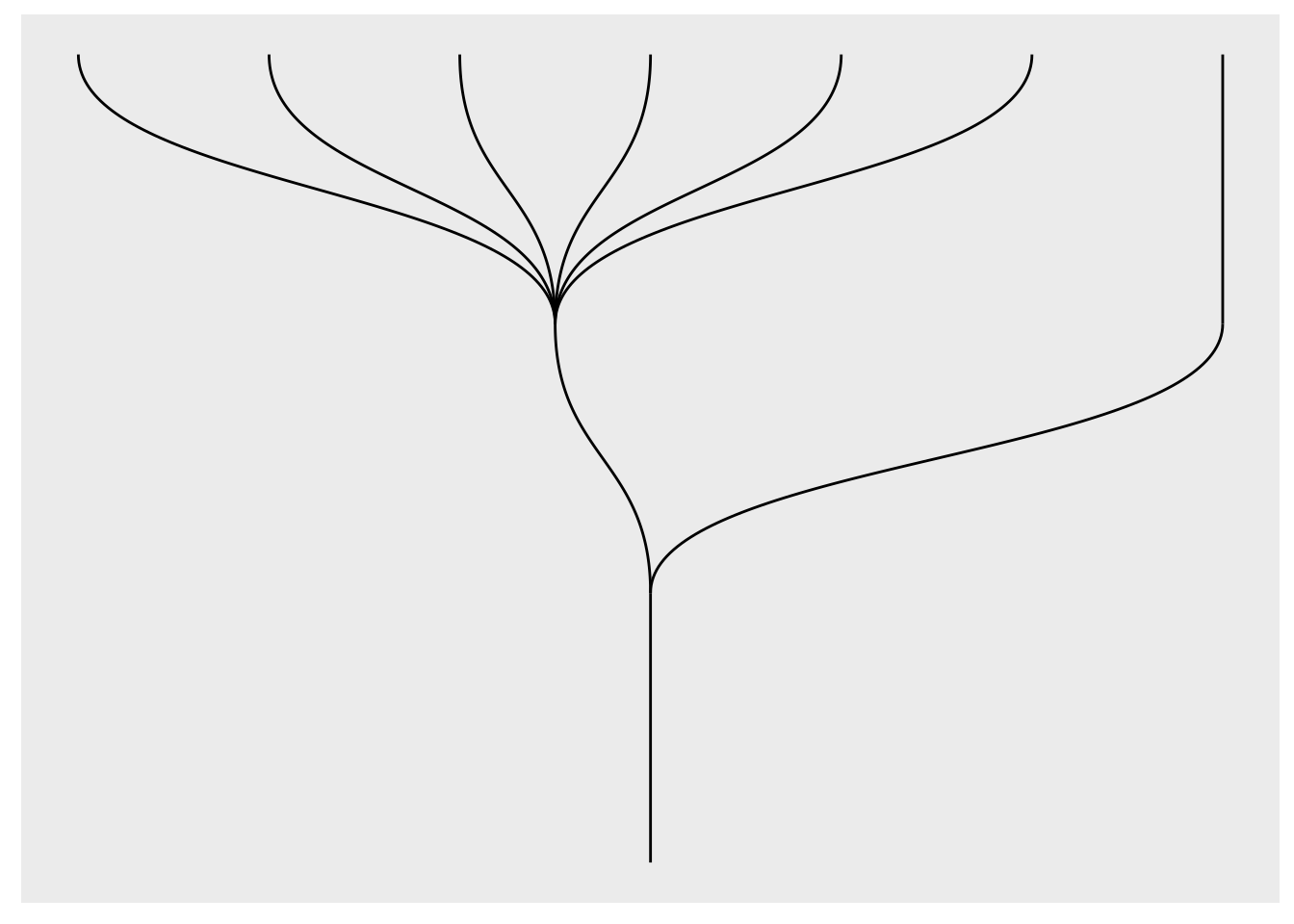
ggraph() — snudd 180 grader.
For å snu det 90 grader, plusser vi på coord_flip() (se Figur 23):
ggraph(df_rel, layout = "dendrogram") +
geom_edge_diagonal() +
coord_flip() 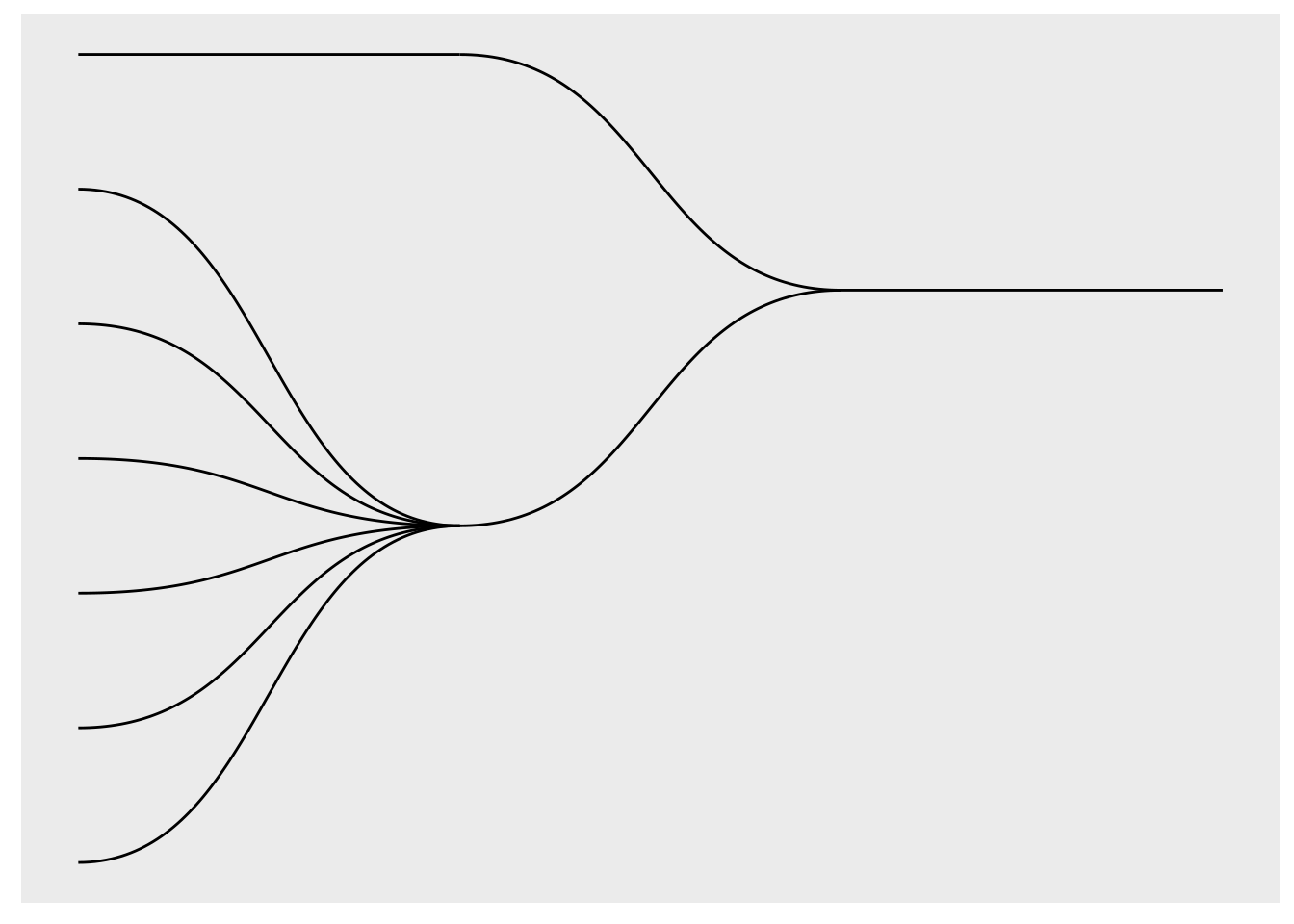
ggraph() — snudd 90 grader.
Hvis vi bytter ut geom_edge_diagonal() med geom_edge_bend(), får vi andre kurver (se Figur 24):
ggraph(df_rel, layout = "dendrogram") +
geom_edge_bend()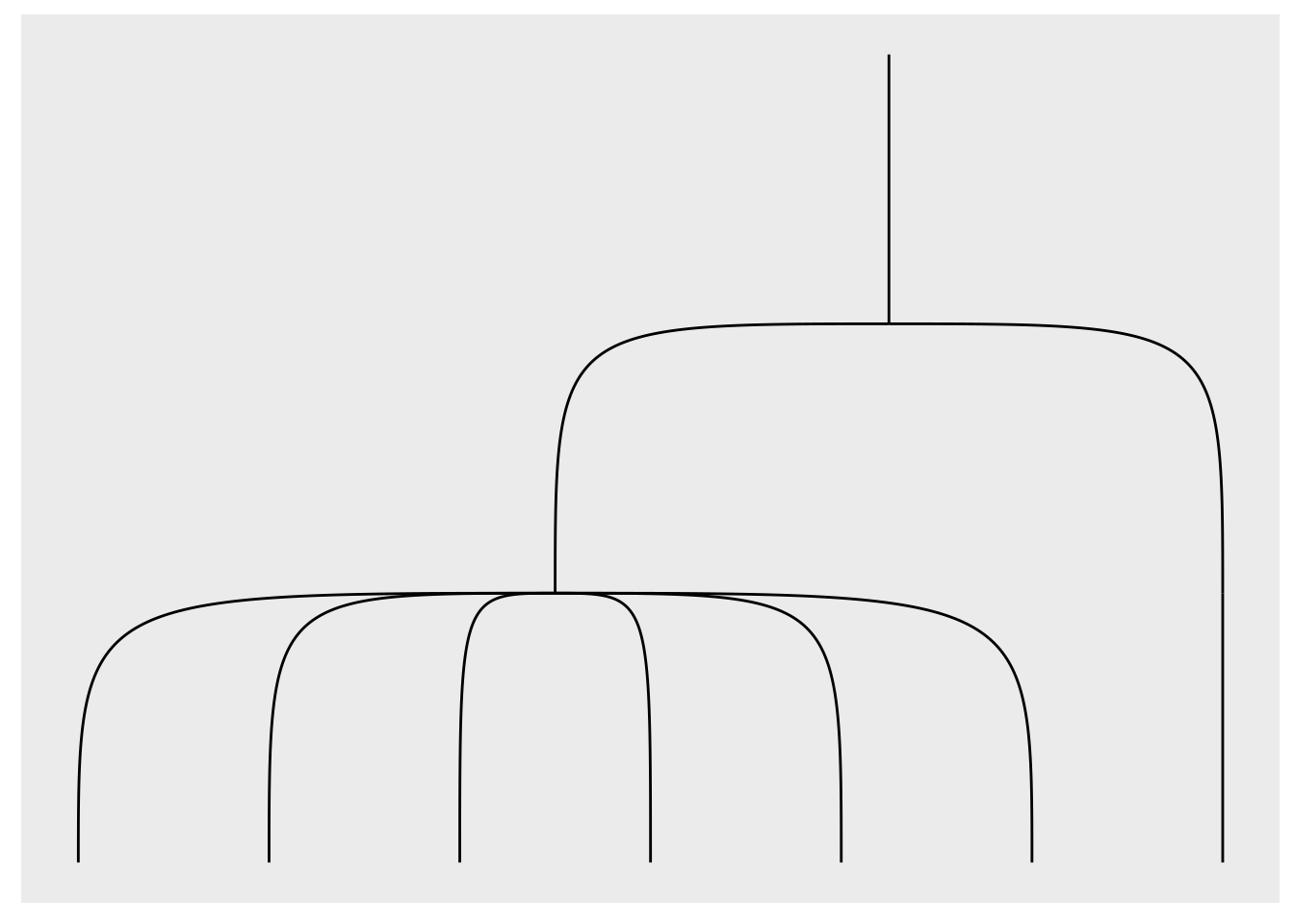
ggraph() — med hardere kurver.
geom_edge_link gir skarpe vinkler (se Figur 25):
ggraph(df_rel, layout = "dendrogram") +
geom_edge_link()
ggraph() — med vinkler.
Mens geom_edge_elbow gir helt rette vinkler (se Figur 26):
ggraph(df_rel, layout = "dendrogram") +
geom_edge_elbow()
ggraph() — med rette vinkler.
Vi kan også bruke R til å lage prosessdiagrammer. La oss si vi ville fremme et argument om at kristendommen svekket toktkulturen i vikingsamfunnene via tre ulike mekanismer — normer mot slaveri, solidaritet med andre kristne og insentiver for handel. Da kunne det passe med et prosessdiagram som går i diamantform fra årsaken via mekanismene til utfallet; altså en boks til venstre (eller oppe), tre bokser i midten, og en boks til høyre (eller nede) (se Figur 27).
graph LR
A --> B
A --> C
A --> D
B --> E
C --> E
D --> E
A(Kristendom)
B(Normer mot slaveri)
C(Solidaritet med andre kristne)
D(Insentiver for handel)
E(Færre tokt)
Det er fullt mulig å lage en slik figur med ggplot eller ggraph, men det enkleste er å bruke diagramopptegningsspråket Mermaid via R-pakken DiagrammeR.DiagrammeR (merk stavingen med stor D og S) er en pakke som ikke lager diagrammer på egen hånd, men tjener som budbringer (såkalt wrapper) mellom R og andre, mer spesialiserte diagrambyggingsspråk, nærmere bestemt Mermaid og GraphViz/DOT. Vi skal fokusere på Mermaid fordi det er enklere og kan brukes direkte i Quarto (se kapittel 13).
R-dimensjonen ved DiagrammeR er veldig enkel; du bruker bare funksjonen DiagrammeR() og setter Mermaid-koden inni, som følger.
## Not Run
DiagrammeR("
<MERMAID-KODE HER>
")Mermaid er eget oppmarkeringsspråk for diagrammer og figurer. Du kan tenke på det som en slags Markdown (se kapittel 13) for diagrammer. Det er lett å lære, har utrolig mange funksjonaliteter, og kan brukes på tvers av kodespråk og tekniske plattformer. Du finner en god innføring i Mermaids syntaks på https://mermaid.js.org/intro/.
Den beste måten å lære Mermaid på er å eksperimentere i en live Mermaid-redigerer slik som https://mermaid.live, for den lar deg se sluttproduktet mens du skriver. Når jeg skal lage et diagram, pleier jeg å skrive Mermaidkoden i en slik redigerer først, for så å lime den inn der jeg trenger den, om det er i et R-skript eller et Quarto-dokument.
Det er lett å lage prosessdiagrammer i Mermaid fordi koden likner på diagrammet du får. For å tegne to bokser A og B med pil fra A til B (se Figur 28), tegner du bokstavelig talt bare en pil, som følger.
# Skrives i https://mermaid.live
graph LR
A --> Bgraph LR A --> B
For å få et prosessdiagram må første linje inneholde ordet graph. Bak graph setter vi retningen som pilene skal følge; enten LR (left-to-right), TB (top-to-bottom), RL eller BT. Deretter definerer vi alle kantene i diagrammet, altså relasjonene mellom nodene, én etter én. Resultatet blir som i Figur 29.
# Skrives i https://mermaid.live
graph LR
A --> B
A --> C
B --> D
C --> Dgraph LR A --> B A --> C B --> D C --> D
Vi kan bestemme teksten inni nodene (se Figur 30) ved å legge til definisjoner med klammer for hver av nodene.
# Skrives i https://mermaid.live
graph LR
A --> B
A --> C
B --> D
C --> D
A[DiagrammeR]
B[Mermaid]
C[GraphViz]
D[Diagram]graph LR A --> B A --> C B --> D C --> D A[DiagrammeR] B[Mermaid] C[GraphViz] D[Diagram]
Merk at Mermaid er svært lite følsom for mellomrom og rekkefølge. Du kan sette ting hvor du vil, så fremt de står på separate linjer (se Figur 31).
# Skrives i https://mermaid.live
graph LR
A[Mermaid]
A-->B
B[Diagram]graph LR
A[Mermaid]
A-->B
B[Diagram]
Formen på nodene kontrolleres med typen klammer i tekstdefinisjonen. Nodenes farge, linjetype, font mm. defineres separat med kommandoen style (se Figur 32). Merk at det finnes mange flere stylingmuligheter enn det jeg viser her.
# Skrives i https://mermaid.live
graph LR
A --> B
A --> C
B --> D
C --> D
A(DiagrammeR)
B[Mermaid]
C[(GraphViz)]
D{Diagram}
style B fill:yellow,stroke-dasharray: 5 5graph LR
A --> B
A --> C
B --> D
C --> D
A(DiagrammeR)
B[Mermaid]
C[(GraphViz)]
D{Diagram}
style B fill:yellow,stroke-dasharray: 5 5
Du kan endre linjetype med andre typer tegn i kantdefinisjonene (se Figur 33). Farge og andre aspekter ved linjen defineres separat med linkStyle etterfulgt av indeksnummeret til kanten/linjen.4 Den du har definert først blir indeks 0.
# Skrives i https://mermaid.live
graph LR
A --- B
A -.- C
B <--> D
C --Tekst--> D
A(DiagrammeR)
B[Mermaid]
C[(GraphViz)]
D{Diagram}
style B fill:yellow,stroke-dasharray: 5 5
linkStyle 0 stroke:red
linkStyle 2 stroke:greengraph LR
A --- B
A -.- C
B <--> D
C --Tekst--> D
A(DiagrammeR)
B[Mermaid]
C[(GraphViz)]
D{Diagram}
style B fill:yellow,stroke-dasharray: 5 5
linkStyle 0 stroke:red
linkStyle 2 stroke:green
Med dette kan vi lage et diagram over vår påståtte sammenheng mellom kristendom og toktkultur. Vi putter Mermaid-koden inn i DiagrammeR() slik at vi kan kjøre den i R. Figur 34 viser sluttproduktet.
DiagrammeR("
graph LR
A --> B
A --> C
A --> D
B --> E
C --> E
D --> E
A(Kristendom)
B(Normer mot slaveri)
C(Solidaritet med andre kristne)
D(Insentiver for handel)
E(Færre tokt)
") graph LR
A --> B
A --> C
A --> D
B --> E
C --> E
D --> E
A(Kristendom)
B(Normer mot slaveri)
C(Solidaritet med andre kristne)
D(Insentiver for handel)
E(Færre tokt)
Merk at DiagrammeR() genererer figurer i HTML-format, så du kan ikke bruke funksjonen når du skal lage PDF-dokumenter i Quarto. Men Quarto lar deg skrive Mermaid-kode i egne Mermaid-kodeblokker slik at behovet for DiagrammeR i praksis bortfaller (se kapittel 13).
ggraphVi kan også bruke R til å fremstille nettverk av ulike slag, det være seg mellom personer eller organisasjoner. Nettverksanalyse er et komplisert felt som vi ikke skal gå inn på her, men vi kan se raskt på hvordan vi kan lage enkle nettverksdiagrammer med pakken ggraph.5
Igjen må vi starte med å bygge en dataramme med grunnlagsdata. En utfordring her er at nettverksdiagrammer ofte involverer mer data enn andre diagrammer. De har gjerne mange noder, og siden hver node kan ha flere kanter, kan datarammen fort bli ganske stor. I praksis lager man sjelden datarammer for nettverksdiagrammer for hånd; man laster ferdige datasett fra andre steder eller genererer dem programmatisk fra andre datakilder.
For illustrasjonens skyld har jeg forberedt et lite nettverksdatasett som ligger i bokens dataarkiv under navnet “kap06_nettverk.csv”. Det inneholder forbindelser mellom personer rundt vikinghøvdingen Tore Hund på Bjarkøy på starten av 1000-tallet. Jeg laget det basert på informasjon om Wikipedia-artikkelen om Tore Hund.6 La oss laste det ned og se på øverste del av det med head().
library(rforalle)
hent_data("kap06_nettverk.csv")Laster ned 'kap06_nettverk.csv' til /home/thomas/repos/github/rforalle_net ..df_nettverk <- read.csv("nettverk.csv")
head(df_nettverk) from to type
1 Tore Hund Tore fra Bjarkøy familie
2 Tore Hund Sigurd Toresson familie
3 Tore Hund Sigrid Toresdatter familie
4 Tore Hund Olav Haraldsson fiende
5 Tore Hund Ranveig familie
6 Tore Hund Kalv Arnesson partnerVi ser at det er strukturert på samme måte som datarammene vi brukte tidligere til ggraph-diagrammer: kanter som rader og to kolonner kalt “from” og “to”. I tillegg har vi nå en kolonne kalt “type”, hvor jeg har kodet for typen relasjon mellom personene, siden dette er noe som egner seg for framstilling i nettverksdiagrammer.
Vi gir datarammen til funksjonen ggraph() for opptegning. For å få nettverksdiagram setter vi parameteret layout til stress. Vi bruker geom_edge_link() for å få rette streker. For å fargelegge forbindelsene etter type, setter jeg inn en aes()-funksjon i geom_edge_link() og assosierer parameteret color med variabelen type. Jeg velger farger med funksjonen scale_edge_color_manual(). I tillegg lager jeg en tittel med labs() og gjør rom rundt nettverket med scale_x_continuous() og scale_y_continuous() (se Figur 35).
ggraph(df_nettverk, layout = 'stress') +
geom_edge_link(aes(color = type)) +
geom_node_point() +
geom_node_label(aes(label = name), size = 2) +
scale_edge_color_manual(values = c('green3', 'red', 'blue')) +
labs(title = 'Tore Hunds verden') +
scale_x_continuous(limits = c(-2,2)) +
scale_y_continuous(limits = c(-2,2.5))Warning: Removed 5 rows containing non-finite outside the scale range
(`stat_edge_link()`).Warning: Removed 3 rows containing missing values or values outside the scale range
(`geom_point()`).Warning: Removed 3 rows containing missing values or values outside the scale range
(`geom_label()`).
Så enkelt kan det gjøres hvis man bare har datarammen klar. Diagrammet kan formateres videre med andre ggraph og ggplot2-funksjoner, men vi stopper her, siden hensikten bare var å illustrere prinsippet.
Før vi avslutter kan vi renske opp i arbeidsområdet vårt med følgende kommando.
# Opprensking
kan_slettes <- list.files(pattern = 'csv$|png$')
file.remove(kan_slettes)Vi har lært å lage fem forskjellige diagramtyper: tidslinjer, Gantt-diagrammer, dendrogrammer, prosessdiagrammer og nettverksdiagrammer. Vi har sett at det finnes pakker spesiallaget for én diagramtype (timelineS), at ggraph kan brukes til flere typer relasjonsdiagrammer, og at vi egentlig kan lage alle diagramtyper i ggplot2. På ny har vi sett at hovedutfordringen ofte er å få strukturert underlagsdataene riktig, særlig i ggraph, hvor vi må tenke på de nye begrepene “noder” og “kanter”. Vi har naturligvis ikke dekket alle mulige diagramtyper, men med verktøyene du nå har lært er du godt rustet til å eksperimentere videre på egen hånd. Du lurer kanskje på hvorfor vi ikke har omtalt en av de mest grunnleggende diagramtypene, nemlig tabeller, men det er fordi vi skal gjøre det i kapittel 13 når vi skal se på Quarto. Nå skal vi videre til et av mine favoritt-temaer i R-universet: kart.
Vær oppmerksom på at dette skriptet henter bilder fra internett via lenkene i df_slag$bilde. Hvis du ikke har nettilkopling, vil du få feilmelding. Noen ganger kan man også få feilmelding som inneholder uttrykket Timeout was reached. Det betyr at R ikke fikk kontakt med serveren som oppbevarer bildet. Det kan være flere årsaker til det, men problemet er normalt midlertidig, så i slike tilfeller anbefaler jeg å prøve igjen litt senere.↩︎
Det finnes en rekke R-pakker som lager en spesifikk type Gantt-diagrammer raskt og enkelt; blant annet vistime, ganttrify, candela, DiagrammeR, plotrix og googleVis. Men de fleste er innrettet mot prosjektplanlegging og genererer diagrammer som etter mitt syn ikke er spesielt pene.↩︎
Merk at mange av parametrene i theme() henviser til x- eller y-aksen og at x nå henviser til aksen med årstall og y til aksen med navn. Det er fordi vi tidligere i skriptet brukte coord_flip(), og theme() forholder seg til grafstrukturen slik den står etter at coord_flip() har vridd om på grafen.↩︎
I skrivende stund er det dessverre ingen enkel måte å kontrollere fargen på pilhodene på; se https://github.com/mermaid-js/mermaid/issues/1236.↩︎
Det er også mulig å lage nettverksdiagrammer med igraph og diagrammeR, men ggraph kommuniserer bedre med resten av GG-systemet.↩︎
https://no.wikipedia.org/wiki/Tore_Hund, konsultert 8. mars 2022.↩︎